

Autor: Rafael Peñaloza
Parte 2. ¿Cuántos zurdos hay?
En el artículo pasado hablamos del problema de predecir cuántos alumnos en una clase o en una escuela serán zurdos, para decidir cuántas bancas especiales se tienen que comprar. En general, no siempre hablaremos de alumnos, zurdos y bancas, sino de una "población" y una "propiedad" que tienen algunos individuos de esta población. Las técnicas de las que vamos a hablar son las mismas sin importar que hablemos de alumnos zurdos, conejos de ojos verdes, o paredes con graffiti. Lo que nos interesa es saber, en un pequeño grupo de individuos, cuántos tendrán la propiedad que estamos estudiando.
Una cosa que escondimos es que para responder a esta pregunta, por lo general tenemos que resolver dos problemas que se complementan: 1) calcular la proporción total de individuos que tienen la propiedad y 2) dada esa proporción, predecir cuántos de los miembros de un grupo tendrán la propiedad.
Empecemos con el primer problema que nos ayudará a entender mejor también el segundo. Además tenemos la ventaja de haber visto los primeros pasos en el artículo anterior, y de las intuiciones de probabilidad que aprendimos en la escuela. En términos prácticos, la proporción de individuos (de la población total) con la propiedad, es la "probabilidad de observar la propiedad en un individuo a caso".
En teoría, en su forma más abstracta, este problema es trivial: observamos a toda la población y contamos cuántos tienen la propiedad. De ahí, todo se resume a una división:

Ok, pero entonces, ¿cuál es la probabilidad de que una persona sea zurda? Para responder esto, tendríamos que ir a contar a cada persona del mundo (más de 7,000,000,000) para ver si son zurdos o diestros. No sólo sería costosísimo, sino que para cuando acabemos, la población ya será otra (sin contar que no podemos conocer la mano dominante de los neonatos). ¿Y qué me dicen de cuántos conejos tienen los ojos verdes?
Incluso si limitamos el espacio (¿cuál es la proporción de mexicanos zurdos?), no es factible hacer las cuentas directamente. Necesitamos un método mucho más eficiente.
Creo que ya se imaginan el método: en lugar de ver a toda la población, nos concentramos en una parte relativamente pequeña para analizarla. Técnicamente, estamos analizando una muestra de la población. La idea es que, si esta muestra es representativa (regresaremos a este punto más adelante), entonces podremos extrapolar la información que nos da a toda la población.
Esto es lo que hicimos en el artículo anterior cuando calculamos la proporción de zurdos en un salón. En ese caso, la muestra era de 37 personas. En general, las muestras pueden ser tan grandes (o tan chicas) como queramos. Pero incluso en el mejor de los casos, surgen algunos detalles que se tienen que resolver.
Exploremos
Para no preocuparnos mucho por los números específicos, pero no dejarlo todo en un mundo abstracto, voy a usar un ejemplo artificial que espero que sea fácil de entender para todos: lanzaremos monedas. Yo lanzo una moneda repetidamente, y quiero saber la proporción de veces que caerá "sol".
Pensemos en una moneda "justa". Nosotros sabemos que el resultado debería ser 0.5; la mitad de las veces caerá "sol" y la otra mitad "águila". Hagan el experimento conmigo y veamos qué pasa.
Hago el primer tiro: "sol". El segundo, "águila"; el tercero "águila"; el cuarto "águila" otra vez, seguido de un "sol". Veamos el resultado hasta ahora:

En estos primeros cinco tiros, vemos que el valor 0.5 que nos esperamos sólo aparece una vez. Dicho de otra forma, en la (pequeña) muestra que hemos generado, la proporción que nos esperamos aparece solo una vez. Si lo pensamos, esto no debería sorprendernos demasiado; de hecho, como estamos usando la fórmula

siempre que el número de tiros (el denominador) sea impar, el resultado será necesariamente distinto de 0.5.
Continuemos lanzando monedas, para ver qué pasa. Para ahorrarles el trabajo, yo ya hice 250 tiros. No les muestro todos los resultados, pero como podrán imaginarse, no se alternan "águila"-"sol"-"águila"-... De vez en cuando nos encontramos secuencias con más soles, y a veces secuencias con más águilas. Veamos un gráfico que muestra cómo evoluciona la proporción de soles durante estos 250 tiros.

La línea roja muestra el punto donde la proporción es 0.5. En los 250 tiros, solamente 23 veces el valor que encontramos es exactamente ese, pero en general vemos que se mantiene cerca de ese número. Otra cosa que vale la pena notar es que a medida que aumentan los tiros, los "saltos" en el valor de la proporción se vuelven más chicos. Esto es porque cuando dividimos entre el número de tiros, la diferencia disminuye proporcionalmente.
Pero notamos otra cosa más interesante: al final de los 250 tiros, la proporción vista está debajo de 0.5. Es exactamente 0.488 que, aunque se acerca bastante a 0.5, no es 0.5. ¿Qué hacemos con este resultado? ¿Qué nos dice?
La lección que quiero dejar clara con todas estas desviaciones es que el método de usar una muestra para conocer la proporción de una población con una propiedad pocas veces será preciso y perfecto. Veámoslo con una imagen.
Suponiendo que nuestra población está dividida de esta forma:

(por ejemplo, la mitad verde representa las "águilas" y la roja los "soles") nos gustaría seleccionar la muestra tal que veamos como resultado algo como

que representa fielmente la proporción original. Lo que puede pasar, en realidad, es que nos topemos con muestras como
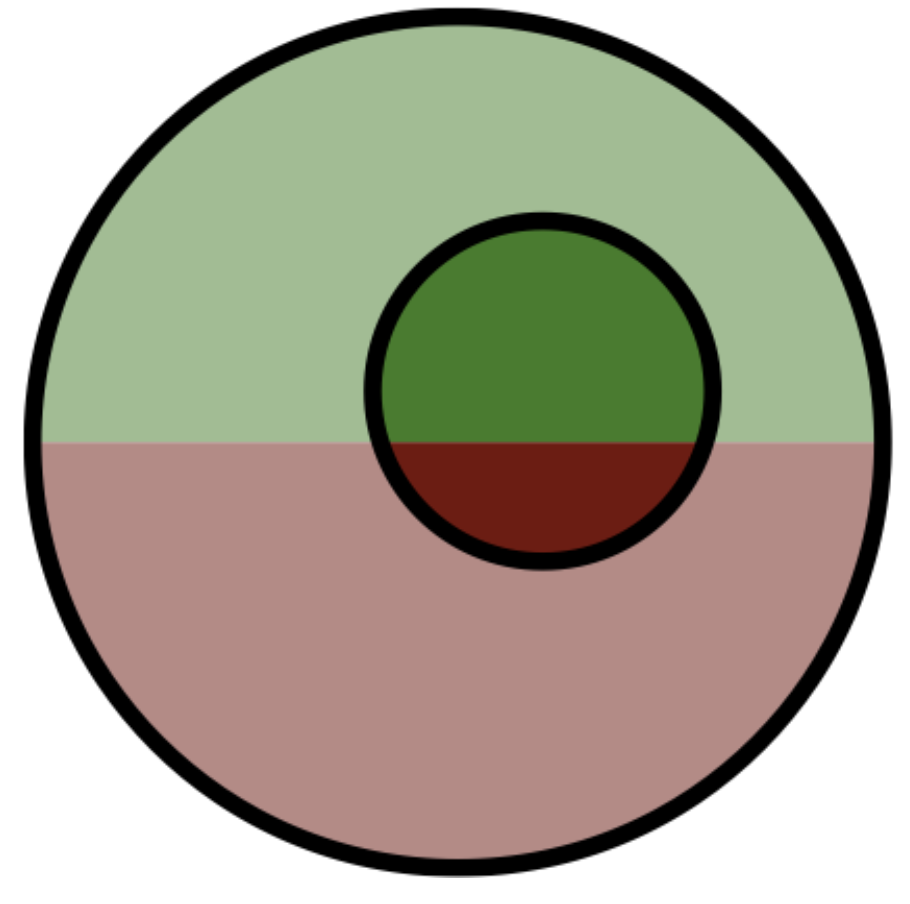
o incluso

No tenemos forma de predecir en cuál caso caeremos al hacer la muestra. Sin embargo, suponiendo que seguimos algunos principios básicos de muestreo para evitar el sesgo hacia una parte de la población (este es un tema al que probablemente regresaremos más adelante) podemos asumir que la muestra es "representativa". O sea, que más o menos refleja a la población como es.
Pero regresamos al meollo del asunto: la muestra, aun representativa, no nos da la proporción exacta que buscamos. ¿Esto quiere decir que no podemos conocer esta proporción? Si. O bueno, no. Lo que quiere decir es que no podemos estar seguros de la proporción exacta, pero podemos aproximarla lo suficiente para fines prácticos.
De esto hablaremos la próxima vez.
Acerca del autor:
Rafael Peñaloza es un profesor de inteligencia artificial en la Universidad de Milano-Bicocca en Italia.
Editores: Emiliano Cantón, Ximena Bonilla